一、虚拟机安装
1.安装VMWARE工作站
自行安装vmware 15/16版
2.创建hadoop虚拟机
新建虚拟机


选择典型模式创建
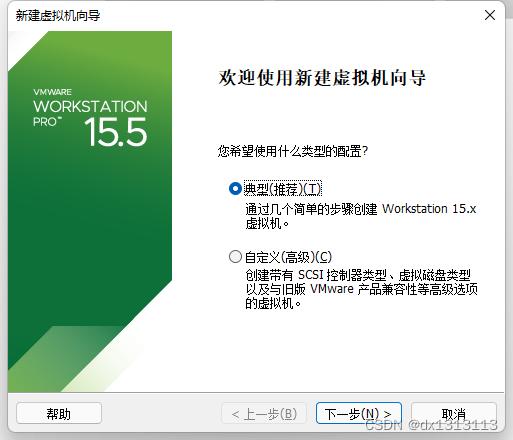
先完成其他配置,后安装系统
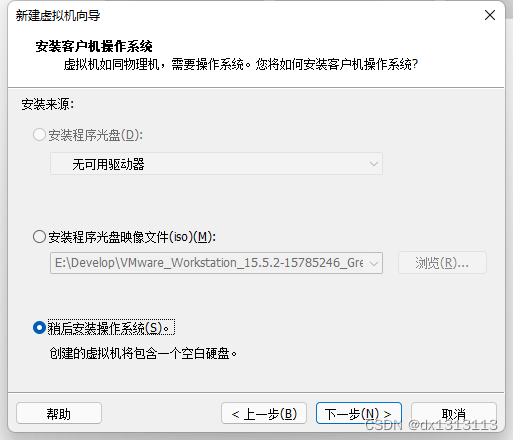
选择系统为对应的centos版本
设置虚拟机名字为hadoop1,同时设置虚拟机的路径
分配空间
自定义硬件,安装系统镜像
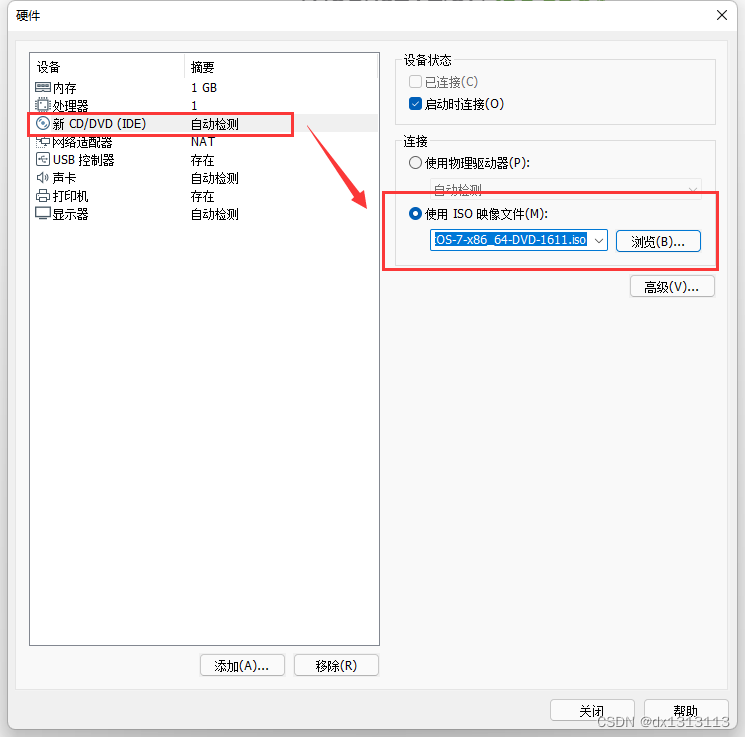
完成安装
完成虚拟机创建和配置
启动虚拟机,等待读条结束
选择系统语言为中文
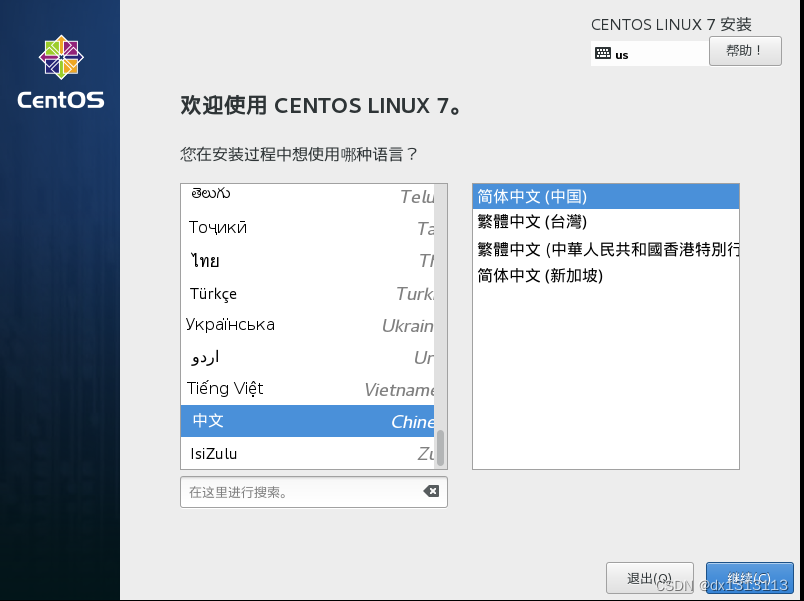
安装信息选择,软件选择(默认最小安装会没有可视化图形界面,如需可视化图形可以勾选为GNOME桌面,右侧除智能卡外全可以勾选)
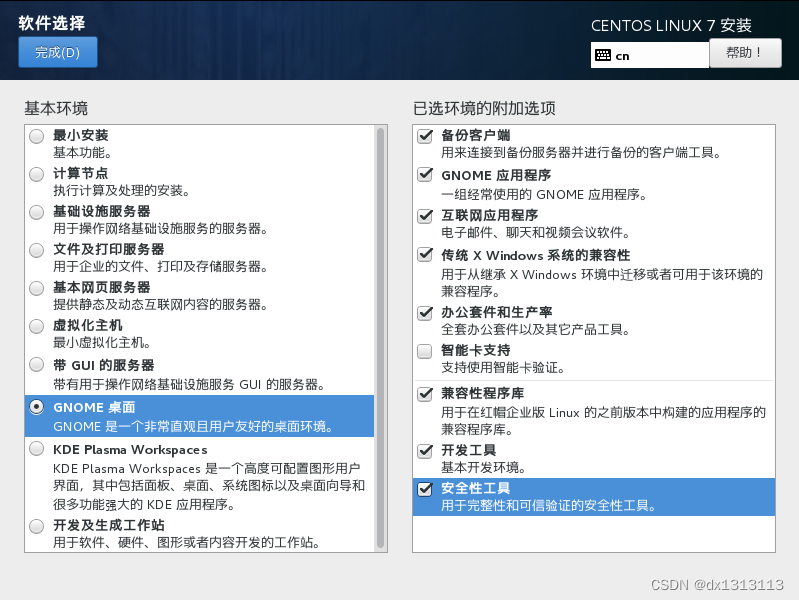
分区默认为自动分区(不会调整分区可以选择默认)
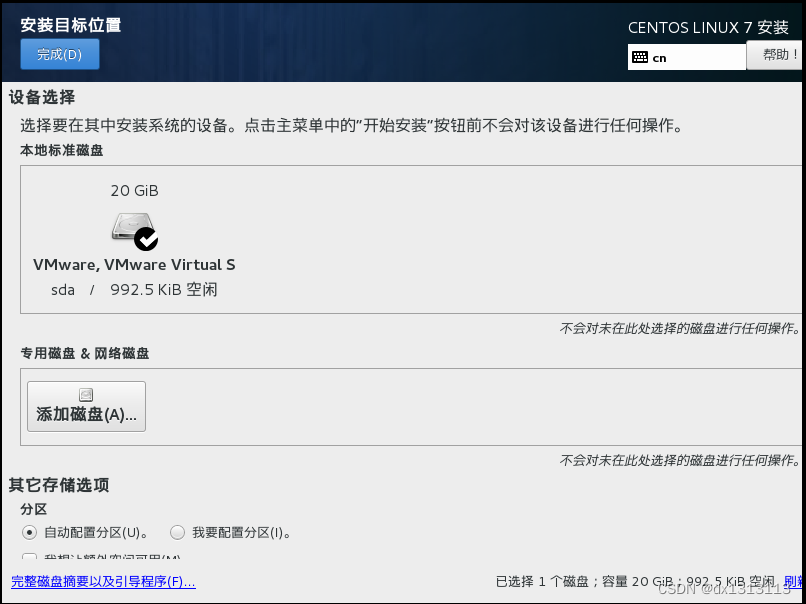
网络配置(可视化图形配置比在终端配置简单,建议在这一步完成配置)
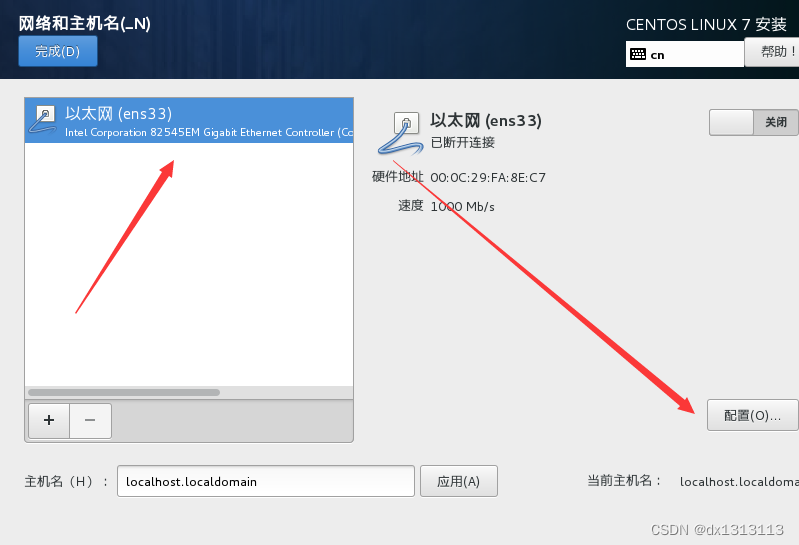
详细网络设置:选择IPV4的DHCP更改为静态地址(手动模式)(IPADDR,GATEWAY,NETMASK,DNS不能照抄,要根据自己硬件网卡虚拟网卡配置)
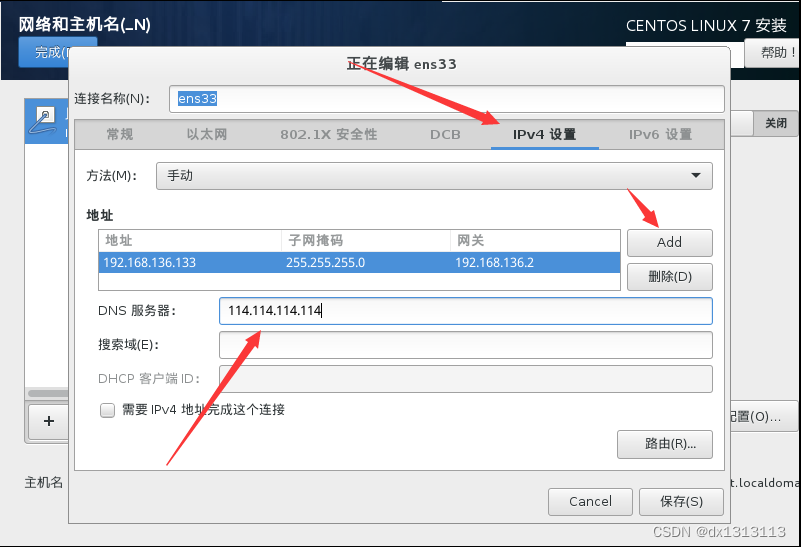
完成设置后退出到上一级,点击启动,如果出现连接受限或者网线已拔出则为配置错误,正常应如下图出现刚才设置的地址网关和掩码,完成网络配置。
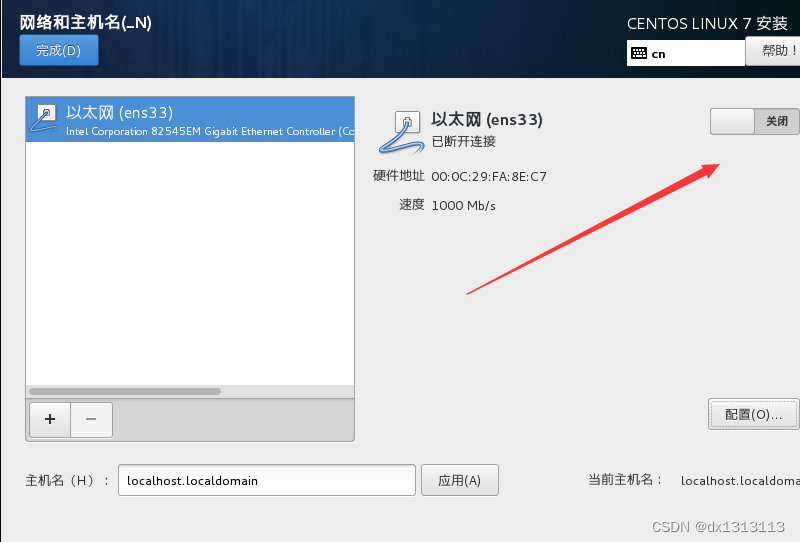
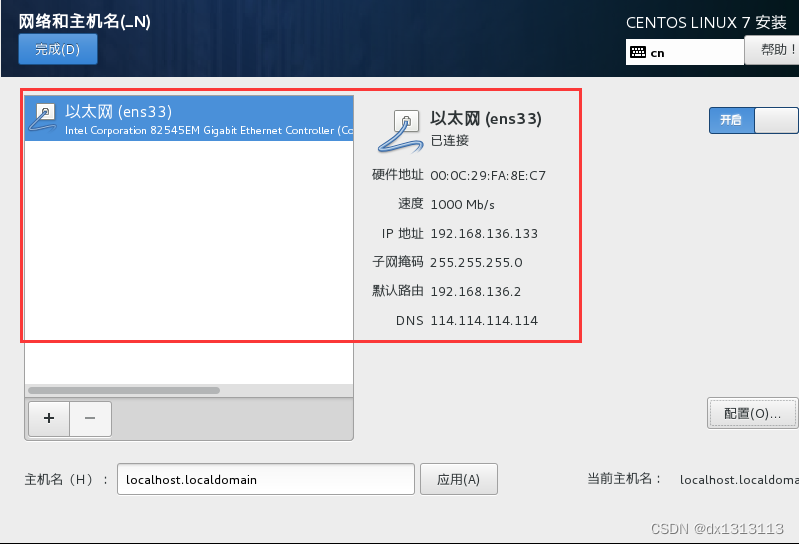
保存退出后主页面出现已连接为成功
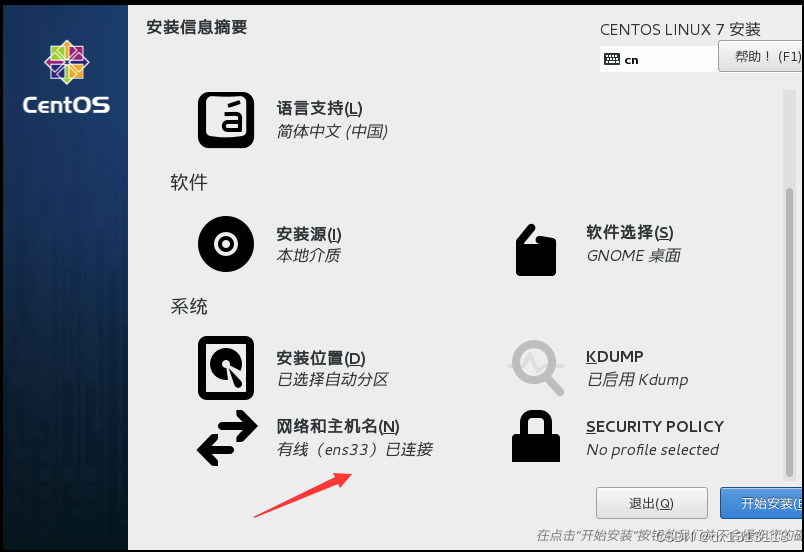
点击开始安装,设置用户和超级管理员
默认超级管理员账户名为root,密码选择为root便于记忆
用户设置(建议用户名为虚拟机名字hadoopxx以便区别,密码与用户名相同。因为会有多台hadoop虚拟机,设置不同密码,不利于记忆。可以将用户提升为管理员)
完成设置后等待安装进度条读完(5-10分钟)
完成后重启虚拟机
重启完后,接受许可证协议,完成配置

输入密码后进入系统(如果没装GNOME是直接进入终端黑窗口)
测试网络
输入百度网址,测试网络是否连接

没装GNOME的终端如下测试
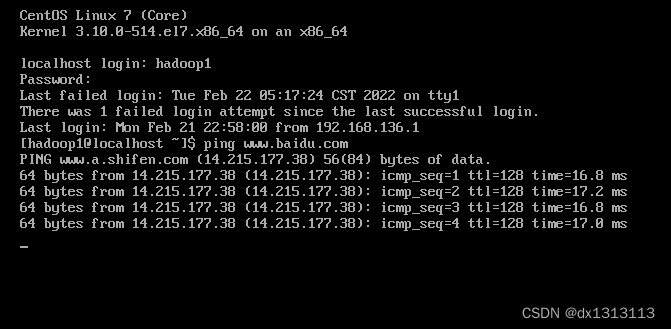
到这一步就完成了CENTOS7的安装和基本配置
3.配置CentOS7
关闭系统和内核自动更新
下载安装yum-cron
yum install yum-cron
安装完之后修改配置文件yum-cron.conf
sudo vi /etc/yum/yum-cron.conf
修改如下内容禁用应用更新
update_messages = no download_updates = no
添加如下代码可以禁用centos7的内核更新
exclude=kernel* exclude=centos-release*
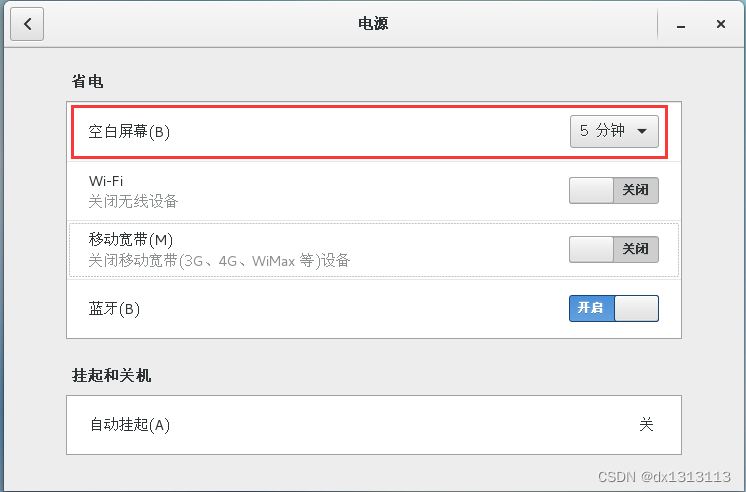
关闭GNOME桌面的自动息屏
空白屏幕设置为从不
二、Lunix(CentOS命令)
文件操作
改变权限
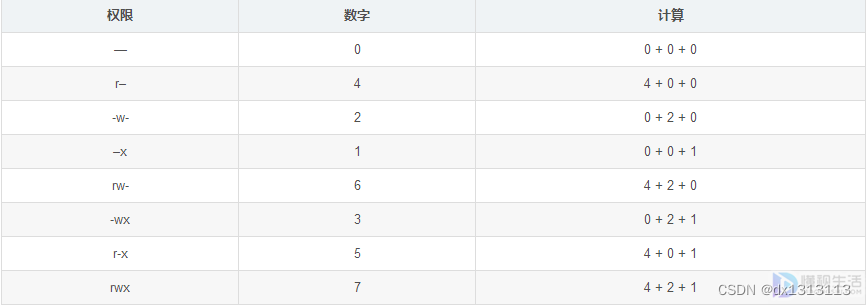
sudo chmod -R (权限代码)文件/文件夹创建文件夹
mkdir 文件夹删除文件(文件夹)
rm -f 文件 rm -rf 文件夹写入(创建)文件
sudo vi 文件名目录
# 跳转到用户的home cd ~ # 跳转到根目录/ cd / # 跳转到上一级 cd .. # 进入当前目录的文件夹 cd ./文件夹 cd 文件夹 #/开头的路径表示绝对路径 非/开头的路径表示相对路径 # 查看目录内所有文件和文件夹 ls # 查看目录内所有文件和文件夹的详细信息 ls -l # 查看目录内的隐藏文件 ls -a应用卸载
yum -y remove 软件包用户和组的创建和权限
创建用户和修改密码
useradd 用户名 passwd 用户名为用户添加sudo权限
给sudoers添加可写权限
chmod -v u+w /etc/sudoers在sudoers文件中添加用户信息(在## Allow root to run any commands anywher 下)
## Allow root to run any commands anywher root ALL=(ALL) ALL dev ALL=(ALL) ALL #新增用户信息取消sudoers写入权限
chmod -v u-w /etc/sudoers新建工作组
groupadd 组名新建用户同时添加工作组,注:-g 所属组 -d 家目录 -s 所用的SHELL
useradd -g 组名 用户名给已有用户添加组
usermod -G 组名 用户名 或者 gpasswd -a 用户名 组名补充
查看用户和用户组的方法 用户列表文件:/etc/passwd 用户组列表文件:/etc/group 查看系统中有哪些用户:cut -d : -f 1 /etc/passwd 查看可以登录系统的用户:cat /etc/passwd | grep -v /sbin/nologin | cut -d : -f 1 查看某一用户:w 用户名 查看登录用户:who 查看用户登录历史记录:last
防火墙
查看防火墙状态
systemctl status firewalld关闭启用防火墙
systemctl stop firewalld systemctl start firewalld关闭selinux
sudo vi /etc/selinux/config #SELINUX=enforcing SELINUX=disabled #关闭selinux系统更新
下载yum-cron
sudo yum install yum-cron启动yum-cron服务
sudo systemctl enable yum-cron.service sudo systemctl start yum-cron.service sudo systemctl status yum-cron.service修改yum-cron配置文件
sudo vi /etc/yum/yum-cron.conf关闭自动更新
update_messages = no download_updates = no忽略内核更新
exclude=kernel* exclude=centos-release*关机和重启
关机和取消关机
shutdown shutdown -c重启
reboot网络
查看网络信息
ifconfig配置网络地址
cd /etc/sysconfig/network-scripts vi 网卡 systemctl restart networkping命令
ping -c次数 ip地址 ping -c3 127.0.0.1修改HOST
sudo vi /etc/hosts进程监控
显示所有进程
ps -ef查找指定进程
ps -ef|grep 搜索名称杀死指定进程
kill -9 pid 显示所有端口号以及程序的pid
netstat -anp查找指定端口号的程序
netstat -anp|grep 端口号下载安装FTP
查询是否安装ftp服务
rpm -qa|grep vsftpd安装ftp服务
yum -y install ftp vsftpd查看配置文件
rpm -qc vsftpd拷贝配置文件
cd /etc/vsftpd sudo cp vsftpd.conf vsftpd.conf.origin修改配置文件
sudo vi /etc/vsftpd/vsftpd.conf1.默认配置: 1>允许匿名用户和本地用户登陆。 anonymous_enable=YES local_enable=YES 2>匿名用户使用的登陆名为ftp或anonymous,口令为空;匿名用户不能离开匿名 用户家目录/var/ftp,且只能下载不能上传。 3>本地用户的登录名为本地用户名,口令为此本地用户的口令;本地用户可以在自己家目录中进行读写操作;本地用户可以离开自家目录切换至有权限访问的其他目录,并在权限允许的情况下进行上传/下载。 write_enable=YES 4>写在文件/etc/vsftpd.ftpusers中的本地用户禁止登陆。 2.配置文件格式: vsftpd.conf 的内容非常单纯,每一行即为一项设定。若是空白行或是开头为#的一行,将会被忽略。内容的格式只有一种,如下所示 option=value 要注意的是,等号两边不能加空白。 3.匿名用户(anonymous)设置 anonymous_enable=YES/NO(YES) 控制是否允许匿名用户登入,YES 为允许匿名登入,NO 为不允许。默认值为YES。 write_enable=YES/NO(YES) 是否允许登陆用户有写权限。属于全局设置,默认值为YES。 no_anon_password=YES/NO(NO) 若是启动这项功能,则使用匿名登入时,不会询问密码。默认值为NO。 ftp_username=ftp 定义匿名登入的使用者名称。默认值为ftp。 anon_root=/var/ftp 使用匿名登入时,所登入的目录。默认值为/var/ftp。注意ftp目录不能是777的权限属性,即匿名用户的家目录不能有777的权限。 anon_upload_enable=YES/NO(NO) 如果设为YES,则允许匿名登入者有上传文件(非目录)的权限,只有在write_enable=YES时,此项才有效。当然,匿名用户必须要有对上层目录的写入权。默认值为NO。 anon_world_readable_only=YES/NO(YES) 如果设为YES,则允许匿名登入者下载可阅读的档案(可以下载到本机阅读,不能直接在FTP服务器中打开阅读)。默认值为YES。 anon_mkdir_write_enable=YES/NO(NO) 如果设为YES,则允许匿名登入者有新增目录的权限,只有在write_enable=YES时,此项才有效。当然,匿名用户必须要有对上层目录的写入权。默认值为NO。 anon_other_write_enable=YES/NO(NO) 如 果设为YES,则允许匿名登入者更多于上传或者建立目录之外的权限,譬如删除或者重命名。(如果anon_upload_enable=NO,则匿名用户 不能上传文件,但可以删除或者重命名已经存在的文件;如果anon_mkdir_write_enable=NO,则匿名用户不能上传或者新建文件夹,但 可以删除或者重命名已经存在的文件夹。)默认值为NO。 chown_uploads=YES/NO(NO) 设置是否改变匿名用户上传文件(非目录)的属主。默认值为NO。 chown_username=username 设置匿名用户上传文件(非目录)的属主名。建议不要设置为root。 anon_umask=077 设置匿名登入者新增或上传档案时的umask 值。默认值为077,则新建档案的对应权限为700。 deny_email_enable=YES/NO(NO) 若是启动这项功能,则必须提供一个档案/etc/vsftpd/banner_emails,内容为email address。若是使用匿名登入,则会要求输入email address,若输入的email address 在此档案内,则不允许进入。默认值为NO。 banned_email_file=/etc/vsftpd/banner_emails 此文件用来输入email address,只有在deny_email_enable=YES时,才会使用到此档案。若是使用匿名登入,则会要求输入email address,若输入的email address 在此档案内,则不允许进入。 4.本地用户设置 local_enable=YES/NO(YES) 控制是否允许本地用户登入,YES 为允许本地用户登入,NO为不允许。默认值为YES。 local_root=/home/username 当本地用户登入时,将被更换到定义的目录下。默认值为各用户的家目录。 write_enable=YES/NO(YES) 是否允许登陆用户有写权限。属于全局设置,默认值为YES。 local_umask=022 本地用户新增档案时的umask 值。默认值为077。 file_open_mode=0755 本地用户上传档案后的档案权限,与chmod 所使用的数值相同。默认值为0666。 5.欢迎语设置 dirmessage_enable=YES/NO(YES) 如果启动这个选项,那么使用者第一次进入一个目录时,会检查该目录下是否有.message这个档案,如果有,则会出现此档案的内容,通常这个档案会放置欢迎话语,或是对该目录的说明。默认值为开启。 message_file=.message 设置目录消息文件,可将要显示的信息写入该文件。默认值为.message。 banner_file=/etc/vsftpd/banner 当使用者登入时,会显示此设定所在的档案内容,通常为欢迎话语或是说明。默认值为无。如果欢迎信息较多,则使用该配置项。 ftpd_banner=Welcome to BOB's FTP server 这里用来定义欢迎话语的字符串,banner_file是档案的形式,而ftpd_banner 则是字符串的形式。预设为无。 6.控制用户是否允许切换到上级目录 在默认配置下,本地用户登入FTP后可以使用cd命令切换到其他目录,这样会对系统带来安全隐患。可以通过以下三条配置文件来控制用户切换目录。 chroot_list_enable=YES/NO(NO) 设置是否启用chroot_list_file配置项指定的用户列表文件。默认值为NO。 chroot_list_file=/etc/vsftpd.chroot_list 用于指定用户列表文件,该文件用于控制哪些用户可以切换到用户家目录的上级目录。 chroot_local_user=YES/NO(NO) 用于指定用户列表文件中的用户是否允许切换到上级目录。默认值为NO。 通过搭配能实现以下几种效果: ①当chroot_list_enable=YES,chroot_local_user=YES时,在/etc/vsftpd.chroot_list文件中列出的用户,可以切换到其他目录;未在文件中列出的用户,不能切换到其他目录。 ②当chroot_list_enable=YES,chroot_local_user=NO时,在/etc/vsftpd.chroot_list文件中列出的用户,不能切换到其他目录;未在文件中列出的用户,可以切换到其他目录。 ③当chroot_list_enable=NO,chroot_local_user=YES时,所有的用户均不能切换到其他目录。 ④当chroot_list_enable=NO,chroot_local_user=NO时,所有的用户均可以切换到其他目录。 7.数据传输模式设置 FTP在传输数据时,可以使用二进制方式,也可以使用ASCII模式来上传或下载数据。 ascii_upload_enable=YES/NO(NO) 设置是否启用ASCII 模式上传数据。默认值为NO。 ascii_download_enable=YES/NO(NO) 设置是否启用ASCII 模式下载数据。默认值为NO。 8.访问控制设置 两种控制方式:一种控制主机访问,另一种控制用户访问。 ①控制主机访问: tcp_wrappers=YES/NO(YES) 设 置vsftpd是否与tcp wrapper相结合来进行主机的访问控制。默认值为YES。如果启用,则vsftpd服务器会检查/etc/hosts.allow 和/etc/hosts.deny 中的设置,来决定请求连接的主机,是否允许访问该FTP服务器。这两个文件可以起到简易的防火墙功能。 比如:若要仅允许192.168.0.1—192.168.0.254的用户可以连接FTP服务器,则在/etc/hosts.allow文件中添加以下内容: vsftpd:192.168.0. :allow all:all :deny ②控制用户访问: 对于用户的访问控制可以通过/etc目录下的vsftpd.user_list和ftpusers文件来实现。 userlist_file=/etc/vsftpd.user_list 控制用户访问FTP的文件,里面写着用户名称。一个用户名称一行。 userlist_enable=YES/NO(NO) 是否启用vsftpd.user_list文件。 userlist_deny=YES/NO(YES) 决定vsftpd.user_list文件中的用户是否能够访问FTP服务器。若设置为YES,则vsftpd.user_list文件中的用户不允许访问FTP,若设置为NO,则只有vsftpd.user_list文件中的用户才能访问FTP。 /etc /vsftpd/ftpusers文件专门用于定义不允许访问FTP服务器的用户列表(注意:如果 userlist_enable=YES,userlist_deny=NO,此时如果在vsftpd.user_list和ftpusers中都有某个 用户时,那么这个用户是不能够访问FTP的,即ftpusers的优先级要高)。默认情况下vsftpd.user_list和ftpusers,这两个 文件已经预设置了一些不允许访问FTP服务器的系统内部账户。如果系统没有这两个文件,那么新建这两个文件,将用户添加进去即可。 9.访问速率设置 anon_max_rate=0 设置匿名登入者使用的最大传输速度,单位为B/s,0 表示不限制速度。默认值为0。 local_max_rate=0 本地用户使用的最大传输速度,单位为B/s,0 表示不限制速度。预设值为0。 10.超时时间设置 accept_timeout=60 设置建立FTP连接的超时时间,单位为秒。默认值为60。 connect_timeout=60 PORT 方式下建立数据连接的超时时间,单位为秒。默认值为60。 data_connection_timeout=120 设置建立FTP数据连接的超时时间,单位为秒。默认值为120。 idle_session_timeout=300 设置多长时间不对FTP服务器进行任何操作,则断开该FTP连接,单位为秒。默认值为300 。 11.日志文件设置 xferlog_enable= YES/NO(YES) 是否启用上传/下载日志记录。如果启用,则上传与下载的信息将被完整纪录在xferlog_file 所定义的档案中。预设为开启。 xferlog_file=/var/log/vsftpd.log 设置日志文件名和路径,默认值为/var/log/vsftpd.log。 xferlog_std_format=YES/NO(NO) 如果启用,则日志文件将会写成xferlog的标准格式,如同wu-ftpd 一般。默认值为关闭。 log_ftp_protocol=YES|NO(NO) 如果启用此选项,所有的FTP请求和响应都会被记录到日志中,默认日志文件在/var/log/vsftpd.log。启用此选项时,xferlog_std_format不能被激活。这个选项有助于调试。默认值为NO。 12.定义用户配置文件 在vsftpd中,可以通过定义用户配置文件来实现不同的用户使用不同的配置。 user_config_dir=/etc/vsftpd/userconf 设置用户配置文件所在的目录。当设置了该配置项后,用户登陆服务器后,系统就会到/etc/vsftpd/userconf目录下,读取与当前用户名相同的文件,并根据文件中的配置命令,对当前用户进行更进一步的配置。 例 如:定义user_config_dir=/etc/vsftpd/userconf,且主机上有使用者 test1,test2,那么我们就在user_config_dir 的目录新增文件名为test1和test2两个文件。若是test1 登入,则会读取user_config_dir 下的test1 这个档案内的设定。默认值为无。利用用户配置文件,可以实现对不同用户进行访问速度的控制,在各用户配置文件中定义local_max_rate=XX, 即可。 13.FTP的工作方式与端口设置 FTP有两种工作方式:PORT FTP(主动模式)和PASV FTP(被动模式) listen_port=21 设置FTP服务器建立连接所监听的端口,默认值为21。 connect_from_port_20=YES/NO 指定FTP使用20端口进行数据传输,默认值为YES。 ftp_data_port=20 设置在PORT方式下,FTP数据连接使用的端口,默认值为20。 pasv_enable=YES/NO(YES) 若设置为YES,则使用PASV工作模式;若设置为NO,则使用PORT模式。默认值为YES,即使用PASV工作模式。 pasv_max_port=0 在PASV工作模式下,数据连接可以使用的端口范围的最大端口,0 表示任意端口。默认值为0。 pasv_min_port=0 在PASV工作模式下,数据连接可以使用的端口范围的最小端口,0 表示任意端口。默认值为0。 14.与连接相关的设置 listen=YES/NO(YES) 设 置vsftpd服务器是否以standalone模式运行。以standalone模式运行是一种较好的方式,此时listen必须设置为YES,此为默 认值。建议不要更改,有很多与服务器运行相关的配置命令,需要在此模式下才有效。若设置为NO,则vsftpd不是以独立的服务运行,要受到xinetd 服务的管控,功能上会受到限制。 max_clients=0 设置vsftpd允许的最大连接数,默认值为0,表示不受限制。若设置为100时,则同时允许有100个连接,超出的将被拒绝。只有在standalone模式运行才有效。 max_per_ip=0 设置每个IP允许与FTP服务器同时建立连接的数目。默认值为0,表示不受限制。只有在standalone模式运行才有效。 listen_address=IP地址 设置FTP服务器在指定的IP地址上侦听用户的FTP请求。若不设置,则对服务器绑定的所有IP地址进行侦听。只有在standalone模式运行才有效。 setproctitle_enable=YES/NO(NO) 设置每个与FTP服务器的连接,是否以不同的进程表现出来。默认值为NO,此时使用ps aux |grep ftp只会有一个vsftpd的进程。若设置为YES,则每个连接都会有一个vsftpd的进程。 15.虚拟用户设置 虚拟用户使用PAM认证方式。 pam_service_name=vsftpd 设置PAM使用的名称,默认值为/etc/pam.d/vsftpd。 guest_enable= YES/NO(NO) 启用虚拟用户。默认值为NO。 guest_username=ftp 这里用来映射虚拟用户。默认值为ftp。 virtual_use_local_privs=YES/NO(NO) 当该参数激活(YES)时,虚拟用户使用与本地用户相同的权限。当此参数关闭(NO)时,虚拟用户使用与匿名用户相同的权限。默认情况下此参数是关闭的(NO)。 16.其他设置 text_userdb_names= YES/NO(NO) 设置在执行ls –la之类的命令时,是显示UID、GID还是显示出具体的用户名和组名。默认值为NO,即以UID和GID方式显示。若希望显示用户名和组名,则设置为YES。 ls_recurse_enable=YES/NO(NO) 若是启用此功能,则允许登入者使用ls –R(可以查看当前目录下子目录中的文件)这个指令。默认值为NO。 hide_ids=YES/NO(NO) 如果启用此功能,所有档案的拥有者与群组都为ftp,也就是使用者登入使用ls -al之类的指令,所看到的档案拥有者跟群组均为ftp。默认值为关闭。 download_enable=YES/NO(YES) 如果设置为NO,所有的文件都不能下载到本地,文件夹不受影响。默认值为YES。
修改配置文件中的listen=YES 和 listen_ipv6=NO,同时禁用掉ftp日志模式,
chroot_local_user=YES ,chroot_list_enable=YES ,chroot_list_file=/etc/vsftpd/chroot_list
service vsftpd restart systemctl status vsftpd systemctl enable vsftpd.servicepasv_enable=YES pasv_min_port=30000 pasv_max_port=30999
设置防火墙对其他服务器来自30000-30999的请求接受
sudo /sbin/iptables -A INPUT -p tcp -s hadoop1 --dport 5021 -i ens33 -j ACCEPT sudo /sbin/iptables -A INPUT -p tcp -s hadoop1 --dport 30000:30999 -i ens33 -j ACCEPT添加ftp用户
sudo useradd -m -d /home/ftpuser -s /sbin/nologin ftpuser sudo passwd ftpuserwindows远程传输
打开cmd输入ftp centos服务器地址 输入ftpuser 和密码ftpuser
ftp终端命令
1.进入ftp环境命令:ftp 2.打开连接:open 192.168.1.106 21 注:(断开连接,close相当于disconnect,但是没有关闭ftp环境) 3.输入用户名:(为空的话输入none) 4.输入密码:(none不用输入密码,直接回车) 注:如果此时用户名或密码错误,但是连接时打开的,可以使用命令 “user 用户名”进入登陆环节 5.查询远程服务器当前路劲:pwd 6.显示远程服务器当前路径下的文件: dir(ls -a和ls -l 也行,ls *通配符) 7.远程服务器切换目录:cd 8.二进制传输:bin 9.上传文件:put(可以直接把文件拖进命令框中,会自动带出文件路径,使用文件的绝对路径也可以上传) 10.下载文件:get 11.打开/关闭交互模式:prompt(批量下载或上传文件前执行该命令,否则上传或下载每个文件都要确 12.批量上传:mput *.txt 13.批量下载:mget * (所有文件)mget *.txt (所有.txt结尾的文件) 14.创建目录:mkdir 15.删除目录:rmdir 16.删除文件:delete 17.批量删除:mdelete *.txt/mdelete * 18.重命名文件:rename a.txt b.txt 19.查看本地当前所在路径,查看路径下的文件:dir (下载文件的本地保存路径) 20.切换本地路径:cd d:\ 结束ftp会话并退出ftp环境:bye(相当于quit)
从windows的终端传输文件到centos
报错553
getsebool -a|grep ftp如果tftp_home_dir ftpd_full_access 和ftpd_use_passive_mode不为on,使用下列命令修改为on
sudo setsebool ftpd_full_access on sudo setsebool ftpd_use_passive_mode on sudo setsebool tftp_home_dir on解决ftpuser传输文件到自己home路径下,其他用户无法使用文件
-
将ftpuser和hadoop用户加入同一个工作组
sudo usermod -G public hadoop1 sudo usermod -G public ftpuser -
将/home/ftpuser的home文件夹所属组从默认的ftpuser改为public
sudo chown ftpuser:public /home/ftpuser -
查看ftpuser的home文件夹权限(默认为drwx------,该权限表示只有自己可读写)
ls -l -
将ftpuser的home文件夹权限改为小组可以读写(777表示最高权限,修改后为drwxrwxrwx)
sudo chmod -R 777 ftpuser -
此时就可以在hadoop1用户下访问ftpuser的home文件夹(可以读写)
SCP拷贝(linux之间)
1、向192.168.10.101推送数据 scp -r /home/swcode/test.txt test1@192.168.1.101:/home/swcode 2、从192.168.10.100拉取数据 scp -r swcode@192.168.1.101:/home/swcode/test.txt /home/swcode/ 3、在192.168.10.101上将192.168.10.100的数据拷贝到192.168.10.102上 scp -r swcode@192.168.1.100:/home/swcode/test.txt swcode@192.168.1.102:/home/swcode/
JAVA安装配置
查看是否有jdk(1.8以上版本)
rpm -qa|grep java卸载自带的jdk(所有通过上面命令查出的都可以删除,删干净后查询java版本提示命令错误)
rpm -e -nodeps 软件 yum -y 软件手动安装jdk
tar -zxvf java压缩包修改文件夹名字
配置环境变量
sudo vi /etc/profile#set java environment JAVA_HOME=/home/hadoop1/java #PATH=$JAVA_HOME/bin:$PATH:. PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin JRE_HOME=$JAVA_HOME/jre CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export JAVA_HOME PATH JRE_HOME
刷新配置文件
source /etc/profile查看jdk版本
java -version查看JAVA_HOME路径
ls -lrt /etc/alternatives/java部分java指令
# 显示所有java进程 jps wget下载器安装
sudo yum install wgetHadoop安装配置
使用wget下载hadoop镜像(由于证书过期,需要以不安全形式连接)
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/stable2/hadoop-2.10.1.tar.gz --no-check-certificate在/home/hadoop1/新建文件夹hadoop
mkdir hadoop将下载的hadoop压缩包移动过去
sudo mv hadoop-2.10.1.tar.gz /home/hadoop1/hadoop解压hadoop
tar -zxvf hadoop-2.10.1.tar.gz hadoop环境配置
-
全局环境变量(/etc/profile和/etc/bashrc)
export HADOOP_HOME=/home/hadoop1/hadoop/hadoop-2.10.1 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
sudo vi /etc/profile sudo vi /etc/bashrc #刷新配置文件 source /etc/profile source /etc/bashrc
输入hadoop version出现版本信息及配置全局环境成功
-
安装配置SSH免密远程登录
-
修改端口(启用端口22)
sudo vi /etc/ssh/sshd_config -
修改防火墙22端口
sudo firewall-cmd --zone=public --add-port=22/tcp --permanent 重启防火墙 systemctl restart firewalld.service 重新载入配置 firewall-cmd --reload 查看 public 区域下所有已打开的端口 firewall-cmd --zone=public --list-ports -
重启服务
sudo systemctl restart sshd -
生成密钥(回车)
ssh-keygen -t rsa -
设置公钥(进入.ssh隐藏文件夹)
cd /home/hadoop1/.ssh cat id_rsa.pub >> authorized_keys sudo chown root:root authorized_keys sudo chmod 600 authorized_keys -
将authorized_keys传输到其他的服务器对应的.ssh文件夹下接受id_rsa.pub,最后保证每台机器都有其余三台的公钥
ssh root@hadoop2 cat ~/.ssh/id_rsa.pub>> authorized_keys # scp -r authorized_keys 用户名@host:存储文件地址 scp -r authorized_keys hadoop2@hadoop2:/home/hadoop2/.ssh -
修改文件夹和文件属性
sudo chmod -R 700 .ssh sudo chmod -R 600 .ssh/authorized_keys -
测试
#重启ssh后在hadoop1上ssh远程免密hadoop2(第一个hadoop2是用户,第二个是hadoop1的host里配置的hadoop2) ssh hadoop2@hadoop2 ssh hadoop2@192.168.136.132 #成功后exit退出 #如果提示要输入密码,请重复上一步修改文件夹和文件属性
-
-
进入/home/hadoop1/hadoop/hadoop-2.10.1/etc/hadoop修改配置文件
-
重点:xml注释里面不要带中文,否则可能会报错
-
hadoop-env.sh
修改JAVA_HOME
#hadoop-2.10.1 里面默认为 export JAVA_HOME=${JAVA_HOME} 可以不修改。 如果没有可以添加为export JAVA_HOME=/home/hadoop1/java sudo vi /home/hadoop1/hadoop/hadoop-2.10.1/etc/hadoop/hadoop-env.sh -
core-site.xml
<configuration> <!-- 指定hdfs的nameservice为myha01 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop1:8020</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop1/hadoop/hadoop-2.10.1/data/hadoopdata/</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>hadoop2:2181,hadoop3:2181,hadoop4:2181</value> </property> <!-- hadoop链接zookeeper的超时时长设置 --> <property> <name>ha.zookeeper.session-timeout.ms</name> <value>1000</value> <description>ms</description> </property> </configuration>
-
hdfs-site.xml
<configuration> <!-- 指定副本数 --> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 配置namenode和datanode的工作目录-数据存储目录 --> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop1/hadoop/hadoop-2.10.1/data/hadoopdata/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop1/hadoop/hadoop-2.10.1/data/hadoopdata/dfs/data</value> </property> <!-- 启用webhdfs --> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <!--指定hdfs的nameservice为myha01,需要和core-site.xml中的保持一致 例如,如果使用"myha01"作为nameservice ID, 并且使用"nn1"和"nn2"作为NameNodes标示符--> <property> <name>dfs.nameservices</name> <value>hadoop1</value> </property> <!--dfs.ha.namenodes.[nameservice id]为在nameservice中每一个NameNode的唯一标识符 配置一个逗号分隔的NameNode ID列表,这将被DataNode识别为所有的NameNode myha01下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.hadoop1</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.hadoop1.nn1</name> <value>hadoop2:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.hadoop1.nn1</name> <value>hadoop2:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.hadoop1.nn2</name> <value>hadoop3:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.hadoop1.nn2</name> <value>hadoop3:50070</value> </property> <!-- 指定 NameNode 的 edits 元数据的共享存储位置。也就是 JournalNode 列表 该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId journalId推荐使用nameservice,默认端口号是:8485 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop2:8485;hadoop3:8485;hadoop4:8485/hadoop1</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop1/hadoop/hadoop-2.10.1/data/journaldata</value> </property> <!-- 开启NameNode失败自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.hadoop1</name> <value> org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider </value> </property> <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 --> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <!-- 使用sshfence隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop1/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <property> <name>ha.failover-controller.cli-check.rpc-timeout.ms</name> <value>60000</value> </property> </configuration>
-
先拷贝一份mapred-site.xml.template 成 mapred-site.xml
sudo cp mapred-site.xml.template mapred-site.xml修改mapred-site.xml配置文件
<configuration> <!-- 指定mr框架为yarn方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 指定mapreduce jobhistory地址 对应服务器的地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop1:10020</value> </property> <!-- 任务历史服务器的web地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop1:19888</value> </property> </configuration>
-
yarn-site.xml
<configuration> <!-- 开启RM高可用 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <!-- 指定RM的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分别指定RM的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop4</value> </property> <!-- 客户端通过该地址向RM提交对应用程序操作 --> <property> <name>yarn.resourcemanager.address.rm1</name> <value>hadoop1:8032</value> </property> <!--ResourceManager 对ApplicationMaster暴露的访问地址。 ApplicationMaster通过该地址向RM申请资源、释放资源等。 --> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>hadoop1:8030</value> </property> <!-- RM HTTP访问地址,查看集群信息--> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>hadoop1:8088</value> </property> <!-- NodeManager通过该地址交换信息 --> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>hadoop1:8031</value> </property> <!--管理员通过该地址向RM发送管理命令 --> <property> <name>yarn.resourcemanager.admin.address.rm1</name> <value>hadoop1:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm1</name> <value>hadoop1:23142</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>hadoop4:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>hadoop4:8030</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>hadoop4:8088</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>hadoop4:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address.rm2</name> <value>hadoop4:8033</value> </property> <property> <name>yarn.resourcemanager.ha.admin.address.rm2</name> <value>hadoop4:23142</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop2:2181,hadoop3:2181,hadoop4:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>86400</value> </property> <!-- 启用自动恢复 --> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!-- 制定resourcemanager的状态信息存储在zookeeper集群上 --> <property> <name>yarn.resourcemanager.store.class</name> <value> org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore </value> </property> </configuration>
-
slaves文件
hadoop1 hadoop2 hadoop3 hadoop4
-
从每个节点启动
hadoop-daemon.sh start journalnode -
将下列端口的防火墙开放
8020/tcp 2181/tcp -> sudo firewall-cmd --zone=public --add-port=2181/tcp --permanent 9000/tcp 50070/tcp 8485/tcp -> sudo firewall-cmd --zone=public --add-port=8485/tcp --permanent 10020/tcp 19888/tcp 8032/tcp 23142/tcp 8032/tcp 8030/tcp 8031/tcp 8033/tcp 23142/tcp 8088/tcp 2181/tcp sudo firewall-cmd --rel
-
查看JPS是否含有journalnode进程
没有就去检查日志
-
格式化namenode(只能在namenode上,即hadoop2和hadoop3)
hadoop namenode -format如果报此类错误No Route to Host from hadoop2/192.168.136.132 to hadoop4:8485 failed,请开启防火墙各台服务器8485端口
-
格式化zkfc (只能在namenode上,即hadoop2和hadoop3)
hdfs zkfc -formatZK提示success及成功
第二台机器格式化时可能会出现提示Proceed formatting /hadoop-ha/hadoop1? (Y or N) 22/02/28 09:50:43 INFO ha.ActiveStandbyElector: Session connected.
输入Y进行下一步
-
启动hdfs
启动hdfs之前先确定zookeeper已启动
zookeeper status启动整个集群
start-dfs.sh
-
tomcat服务器安装和配置
在/home/hadoop1/中新建tomcat文件夹
mkdir tomcat移动tomcat压缩包到tomcat文件夹内
mv apache-tomcat-10.1.0-M10.tar.gz /home/hadoop1/tomcat解压
tar -zxvf apache-tomcat-10.1.0-M10.tar.gz重命名
mv apache-tomcat-10.1.0-M10 tomcat-10.1启动tomcat服务器
-
进入tomcat的bin目录
cd /home/hadoop1/tomcat/tomcat-8.5/bin授权
sudo chmod +x /home/hadoop1/tomcat/tomcat-8.5/bin/*.sh -
开放8080端口
为了能远程访问centos上的tomcat,需要开启防火墙的8080端口
查看防火墙状态 firewall-cmd --state --zone=public 作用于公共域 --add-port=8080/tcp 添加tcp协议的端口8080 --permanent 永久生效,没有此参数,该命令只能维持当前服务生命周期 firewall-cmd --zone=public --add-port=8080/tcp --permanent 重启防火墙 systemctl restart firewalld.service 重新载入配置 firewall-cmd --reload 查看 public 区域下所有已打开的端口 firewall-cmd --zone=public --list-portstomcat服务器配置
sudo vi /etc/systemd/system/tomcat.service将下列配置写入tomcat.service
[Unit] Description=Tomcat8.5 After=syslog.target network.target remote-fs.target nss-lookup.target [Service] Type=oneshot ExecStart=/home/hadoop1/tomcat/tomcat-8.5/bin/startup.sh ExecStop=/home/hadoop1/tomcat/tomcat-8.5/bin/shutdown.sh ExecReload=/bin/kill -s HUP $MAINPID RemainAfterExit=yes [Install] WantedBy=multi-user.target
sudo vi /home/hadoop1/tomcat/tomcat-8.5/bin/setenv.sh
# 设置JAVA_HOME export JAVA_HOME=/home/hadoop1/java export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH export CATALINA_HOME=/home/hadoop1/tomcat/tomcat-8.5 export CATALINA_BASE=/home/hadoop1/tomcat/tomcat-8.5 # 设置Tomcat的PID文件 CATALINA_PID="$CATALINA_BASE/tomcat.pid" # 添加JVM选项 JAVA_OPTS="-server -XX:PermSize=128M -XX:MaxPermSize=512m -Xms512M -Xmx512M -XX:MaxNewSize=128m"
sudo vi /usr/lib/systemd/system/tomcat.service
[Unit] Description=tomcat8.5 After=syslog.target network.target remote-fs.target nss-lookup.target [Service] Type=forking PIDFile=/home/hadoop1/tomcat/tomcat-8.5/tomcat.pid ExecStart=/home/hadoop1/tomcat/tomcat-8.5/bin/startup.sh ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s QUIT $MAINPID PrivateTmp=true [Install] WantedBy=multi-user.target
重载设置
systemctl daemon-reload -
启动tomcat服务
./startup.sh -
访问tomcat测试
-
设置自启动
配置bin/setclassPath.sh,bin/startup.sh,中的JAVA_HOME和JRE_HOME
sudo vi /home/hadoop1/tomcat/tomcat-8.5/bin/setclasspath.sh sudo vi /home/hadoop1/tomcat/tomcat-8.5/bin/startup.sh export JAVE_HOME=/home/hadoop1/java export JRE_HOME=/home/hadoop1/java/jre新建bin/setenv.sh写入
# tomcat的PID文件 CATALINA_PID="/home/hadoop1/tomcat/tomcat-8.5/tomcat.pid" # 添加JVM选项 JAVA_OPTS="-server -XX:PermSize=256M -XX:MaxPermSize=1024m -Xms512M -Xmx1024M -XX:MaxNewSize=256m"设置自启
sudo systemctl enable tomcat.service查看是否自启
systemctl list-unit-files | grep enabled
zookeeper安装配置(只安装配置三台非主节点)
下载解压安装包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/apache-zookeeper-3.6.3-bin.tar.gz tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz mv apache-zookeeper-3.6.3-bin zookeeper修改配置文件
-
生成配置文件
cd zookeeper/conf cp zoo_sample.cfg zoo.cfg -
修改配置文件
vi zoo.cfg修改dataDir路径为hadoop/data/zkdata和dataLogDir为hadoop/log/zklog
-
新建hadoop/data/zkdata和hadoop/log/zklog
mkdir /home/hadoop2/hadoop/hadoop-2.10.1/data/zkdata mkdir /home/hadoop2/hadoop/hadoop-2.10.1/log/zklog -
添加server.1,server.2,server.3的host和端口
server.1=hadoop2:2888:3888 server.2=hadoop3:2888:3888 server.3=hadoop4:2888:3888 -
进入dataDir路径,新建文件myid,添加本机id(server.1=hadoop2:2888:3888的1)
cd /home/hadoop2/hadoop/hadoop-2.10.1/data/zkdata vi myid 或者 echo 1 > myid1
-
配置环境变量
修改.bashrc(个人的)
vi ~/.bashrc # Zookeeper export ZOOKEEPER_HOME=/home/hadoop2/zookeeper-3.6.3 export PATH=$PATH:$ZOOKEEPER_HOME/bin重启配置文件
source ~/.bashrc开放端口2888和3888
sudo firewall-cmd --zone=public --add-port=2888/tcp --permanent sudo firewall-cmd --zone=public --add-port=3888/tcp --permanent sudo firewall-cmd --reload启动三台服务器上的ZK
#启动服务 zkServer.sh start #关闭服务 zkServer.sh stop #查看服务 zkServer.sh status #查看进程QuorumPeerMain jps |grep QuorumPeerMain如果有服务器无法启动可以先尝试启动其他的服务器
启动成功后查看状态(1个Leader ,两个Follower)
-
三、Hadoop集群启动
流程
-
启动234服务器的zookeeper
-
启动1234服务器的hadoop
-
启动1服务器的hdfs
以上内容由“WiFi之家网”整理收藏!。
原创文章,作者:192.168.1.1,如若转载,请注明出处:https://www.224m.com/232194.html
